
티스토리 뷰
이 글은 우아한형제들 기술블로그에 기고한 글과 동일한 글입니다.
제목의 밈은 조림요정의 휴먼강록체입니다.
Intro
평화로운 2020년 9월의 어느 날...
데일리 미팅을 마치고 일감을 정리하던 저에게 한 가지 요청이 들어왔습니다.
"우빈님 여기 로직이 오래 걸리면 90초 넘게 걸리고 있는데 한번 개선할 수 있을지 확인 부탁드려요."
'읭 아니 대체 어떤 레거시길래 90초씩이나 걸리는거야'
라고 생각하며 코드를 열어서 확인했는데요.

범인은 다섯 달 전의 저였습니다.
개발자들에게는 흔히 있는 일이라고 하는데... 저만 겪고 있는 건 아니죠?
오늘 포스팅에서는 위 레거시를 생산하게 된 배경과, 그 해결과정을 정리해서 공유해보려고 합니다.
크게 어려운 내용은 아니니 해결해가는 과정 자체에 포인트를 두고 가볍게 읽어주시면 감사하겠습니다. 😉
5개월 전...
입사 후 신규입사자 온보딩 과정을 마무리하고, 팀에서 가장 먼저 받은 첫 번째 과제는 정산시스템 어드민(관리자 페이지)의 최초 진입 화면인 대시보드를 만드는 과제였습니다.
당시 정산 어드민에 로그인한 후 보이는 첫 화면은 좌측 메뉴 바를 제외하고는 특별하게 제공되는 것이 없는 빈 화면이었는데요.
관리자 페이지를 사용하시는 기획/운영자 분이 수시로 확인하면 좋을 각종 실시간 지표들을 화면에 구축하는 것이 바로 해당 과제의 내용이었습니다.
배치 모니터링

요구사항에 있는 많은 지표들 중 하나는, 정산시스템의 허리를 담당하고 있는 수십 개의 배치를 개발자가 아닌 운영자 분이 모니터링할 수 있도록 하는 배치 모니터링 지표였습니다.
아래에 이어서 나오는 배치 모니터링 분석에 대한 내용은 당시에 태현님이 많은 도움을 주셨습니다 🙏
배치 모니터링 지표에서는 그날 수행될 예정인 배치가 어떤 것인지 파악할 수 있어야 했고, 해당 배치의 실시간 상태를 확인할 수 있어야 했습니다.
또한 각 배치의 활성화(on/off) 상태와 더불어 수행 시작/종료 시간도 트래킹할 수 있어야 했습니다.
즉, 정리하자면 다음과 같은 정보들을 어디선가 얻어오거나 필요에 따라 새롭게 정의해야 했습니다.
- 배치의 가장 최근 작업 상태 (수행중/성공/실패/수행예정)
- 활성화 여부
- 작업 시작시간/종료시간
- 작업 주기 (배치가 수행될 예정인지를 판별하기 위함)
- 운영자가 매일/영업일/매월 1일/수시 등으로 사전에 정의하여 지정
저희 팀은 배치 관리 도구로 젠킨스(Jenkins)를 사용하고 있는데요.

정산시스템에서 이 젠킨스를 통해 관리하고 있는 배치의 형태를 파악해보니 다음과 같이 세 종류로 구분할 수 있었습니다. (이름은 임의로 붙여봤습니다.)

- Simple Job
- 가장 단순한 형태의 배치로, Spring Batch와 Jenkins Job이 1:1인 경우
- Trigger Job
- 하나의 주요한 배치 A가 있고, A 배치에게 다양한 파라미터를 제공하며 수행 요청만 하고 자기자신은 종료되는 배치
- 배치 A와 1:N 관계
- 예를 들어, 배치 A에 1번 파라미터를 제공하는 배치, 배치 A에 2번 파라미터를 제공하는 배치 등
- Pipeline Job
- 여러 개의 배치 Job을 순차적으로 실행할 수 있는 파이프라인 배치
- 파이프라인 Script로 하위 배치 Job를 단계별로 지정해서 실행
이렇게 구해야 하는 배치의 정보와, 현재 배치 시스템의 상황을 파악하고 나니 다음과 같은 고민이 있었습니다.
💡 수십 개의 배치가 수행된 상태를 실시간으로 조회하기 위해 어떤 방법을 선택해야 하는가?
크게는 두 가지 방법을 놓고 고민했는데요.
바로 Spring Batch Metadata Tables와 젠킨스 API 였습니다.
Spring Batch Metadata Tables
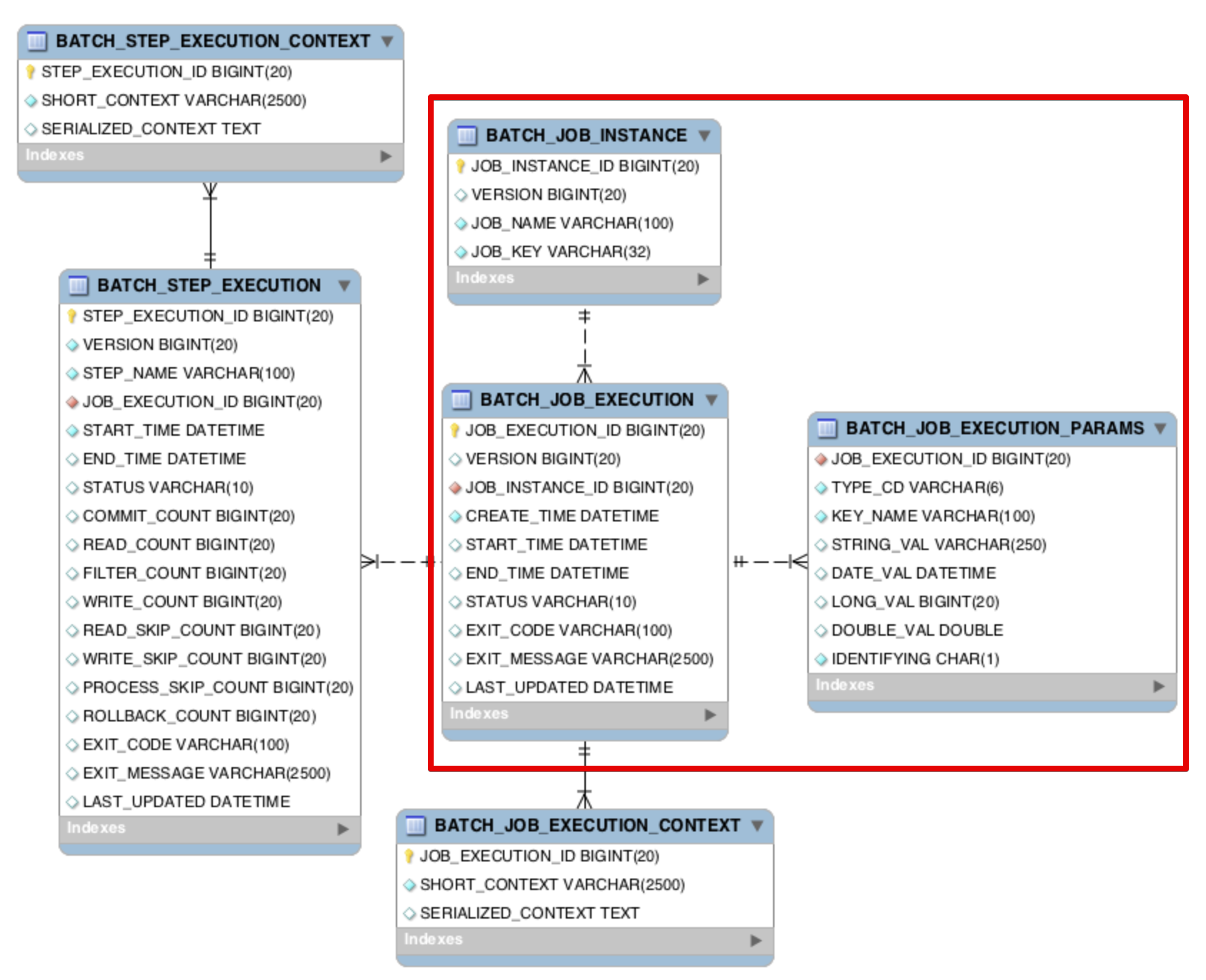
Spring Batch Metadata Tables(Schema)는 Spring Batch로 수행된 모든 Job에 대한 정보를 가지고 있는 메타데이터 테이블입니다.
위 요구사항과 관련한 정보들을 가져오기 위해서는, 그중에서도 BATCH_JOB_INSTANCE 테이블과 BATCH_JOB_EXECUTION 테이블, 그리고 BATCH_JOB_EXECUTION_PARAMS 테이블을 참고해야 할 것으로 보였습니다.
Spring Batch를 사용하시는 분들은 대부분 아시겠지만, 한번 간단하게 정리해보자면 다음과 같습니다.
- BATCH_JOB_INSTANCE
- Job Parameter에 따른 배치 수행 정보를 기록
- 동일 파라미터로는 데이터가 발생하지 않음 (배치 수행 불가)
- BATCH_JOB_EXECUTION
- BATCH_JOB_INSTANCE의 자식 테이블로, 모든 성공/실패 내역을 가지고 있음
- BATCH_JOB_EXECUTION_PARAMS
- 실제 수행되었던 배치의 구체적인 모든 파라미터가 기록되는 테이블
더 상세한 내용은 jojoldu님의 블로그를 참고해보시면 좋습니다.
Spring Batch Metadata Tables와 위 요구사항을 매칭해보니, 다음과 같은 문제점들이 보였습니다.
- 파이프라인 Job은 메타테이블이 직접적으로 관리하고 있지 않기 때문에 추가 작업이 필요하다.
- 파이프라인 하위 배치들의 순서를 알아야 하고, 순서가 달라지면 코드 변경 및 배포가 필요하다.
- 첫 수행 배치 Job과 마지막 수행 배치 Job의 시간을 조회해야 한다.
- 여러 테이블의 조인이 필요하다.
- Jenkins Job의 활성화 여부는 Jenkins API로만 얻어올 수 있다.
- (아래 캡쳐 참조) 배치 활성화 on/off 는
빌드 안함체크로 관리하고 있다.
- (아래 캡쳐 참조) 배치 활성화 on/off 는

Jenkins API
다음으로는 Jenkins의 API에 대해 고민했는데요.
Jenkins API wiki가 있긴 하지만, 어떤 API가 있는지 정확하게 정리해주지는 않고 있습니다.
하지만 우리의 요구사항에 대한 정보를 얻어오기 위해서는 다음 2개의 API면 충분합니다.
첫 번째로 Job에 대한 정보를 받아오는 API 입니다. ${Jenkins_URL}/job/${job_name}/api/json 으로 요청할 수 있습니다. (Jenkins job 화면에서 /api/json 을 붙여서 확인해보실 수 있습니다.)
주요한 필드만 기술해보면 아래와 같습니다. (테스트 환경의 IP 정보는 JENKINS_URL로 표시했습니다.)
{
"description": "",
"displayName": "test-01",
"fullDisplayName": "test-01",
"fullName": "test-01",
"name": "test-01",
"url": "http://JENKINS_URL/job/test-01/",
"buildable": true,
"builds": [
{
"_class": "hudson.model.FreeStyleBuild",
"number": 3,
"url": "http://JENKINS_URL/job/test-01/3/"
},
{
"_class": "hudson.model.FreeStyleBuild",
"number": 2,
"url": "http://JENKINS_URL/job/test-01/2/"
},
{
"_class": "hudson.model.FreeStyleBuild",
"number": 1,
"url": "http://JENKINS_URL/job/test-01/1/"
}
],
"color": "blue",
"firstBuild": {
"_class": "hudson.model.FreeStyleBuild",
"number": 1,
"url": "http://JENKINS_URL/job/test-01/1/"
},
"inQueue": false,
"keepDependencies": false,
"lastBuild": {
"_class": "hudson.model.FreeStyleBuild",
"number": 3,
"url": "http://JENKINS_URL/job/test-01/3/"
},
"lastCompletedBuild": {
"_class": "hudson.model.FreeStyleBuild",
"number": 3,
"url": "http://JENKINS_URL/job/test-01/3/"
},
"lastFailedBuild": {
"_class": "hudson.model.FreeStyleBuild",
"number": 2,
"url": "http://JENKINS_URL/job/test-01/2/"
},
"lastStableBuild": {
"_class": "hudson.model.FreeStyleBuild",
"number": 3,
"url": "http://JENKINS_URL/job/test-01/3/"
},
"lastSuccessfulBuild": {
"_class": "hudson.model.FreeStyleBuild",
"number": 3,
"url": "http://JENKINS_URL/job/test-01/3/"
},
"lastUnstableBuild": null,
"lastUnsuccessfulBuild": {
"_class": "hudson.model.FreeStyleBuild",
"number": 2,
"url": "http://JENKINS_URL/job/test-01/2/"
},
"nextBuildNumber": 4
}Job API에서 눈여겨 볼 정보들은 다음과 같습니다.
- name
- Job 이름
- buildable
- 활성화 여부 (
빌드 안함체크 여부)
- 활성화 여부 (
- lastBuild, lastCompletedBuild, lastFailedBuild
- 최신 빌드 URL, 최신 성공 빌드 URL, 최신 실패 빌드 URL
두 번째로는 Build에 대한 정보를 받아오는 API 입니다. ${Jenkins_URL}/job/${job_name}/${build_id}/api/json 으로 요청할 수 있습니다.
(상세 Build 화면에서 /api/json 을 붙여서 확인해보실 수 있습니다.)
마찬가지로 주요한 필드만 기술해보면 아래와 같습니다.
{
"building": false,
"displayName": "#3",
"duration": 34,
"estimatedDuration": 116,
"fullDisplayName": "test-01 #3",
"id": "3",
"keepLog": false,
"number": 3,
"result": "SUCCESS",
"timestamp": 1616924008157,
"url": "http://JENKINS_URL/job/test-01/3/"
}Build API에서 눈여겨 볼 정보는 다음과 같습니다.
- building
- 현재 수행중인지 여부
- duration
- 수행된 시간
- result
- 빌드 결과
- timestamp
- 수행 시작 시간
- timestamp에 duration을 더해서 환산하면 수행 종료 시간이 됩니다.
(위 2개 API를 제외한 다른 API가 궁금하시면 Jenkins API wrapping 라이브러리인 Jenkins-rest를 참고해보셔도 좋습니다!)
마찬가지로 Jenkins API와 위 요구사항을 매칭해보니, 다음과 같은 문제점들이 보였습니다.
- Trigger Job은 다른 배치를 Trigger만 하고 종료되기 때문에, 정확한 수행시간 등을 모니터링할 수 없다.
- 하나의 배치 당 2번의 API 조회가 필요하다.
Jenkins API를 사용하는 방법에서 가장 큰 문제는, 하나의 API만 가지고는 우리가 필요한 모든 정보를 얻을 수 없다는 것입니다.
즉, Job API에서는 어디로 가야 Build 정보가 있는지 Build 번호와 URL만 던져줄 뿐이고, 그렇게 찾아간 Build API에서는 반대로 Job에 대한 상세 정보(활성화 여부 등)를 확인할 수 없습니다.
이렇게 되면 하나의 배치 당 Job API 한번, Build API 한번, 총 2번 API를 찔러야 하고, 결국 모니터링하려는 수십 개의 배치의 2배 만큼 API 호출을 해야하는 상황이었습니다.
아니 집사님... 친절하게 한번에 다 알려주시면 안됩니까...

Spring Batch Metadata Tables와 Jenkins API 중 고민하다가, 어차피 활성화 여부는 API를 통해 얻어와야 하고, 정보를 조합하기에도 API 쪽이 더 낫다고 생각해 후자를 선택하게 되었습니다.
장단점에 따라 두 방법을 섞어서 쓰기에는 개발 기간이나 복잡도 측면에서 적합하지 않다고 판단하였습니다.
집사가 일을 대충하면 목마른 주인이 우물을 파야죠. 연장 가져오겠습니다. ⛏
해보자, 조회!
전체적인 배치 모니터링플로우는 다음과 같습니다.
- 운영자가 모니터링하고 싶은 배치를 어드민에 Job 이름/관리용 이름/작업주기/조회유무 정보와 함께 등록한다.
- 등록할 때 Job 이름(batchId)을 기준으로 Jenkins API를 찔러서, 실제 운영되고 있는 배치인지 확인한다.
- 배치가 존재한다면, monitoring_batch라는 별도의 모니터링용 배치 관리 테이블에 저장한다.
- 조회 시에는 등록한 batchId와 작업주기를 기준으로 당일 조회 대상인 배치 리스트를 가져와 일괄 조회한다.
먼저, 필요한 API 정보에 맞게 JobInfo와 BuildInfo를 정의했습니다.
@ToString
@Getter
@NoArgsConstructor
public class JobInfo {
private String description;
private String displayName;
private String name;
private boolean buildable;
private String url;
private List<BuildUrl> builds;
private BuildUrl firstBuild;
private BuildUrl lastBuild;
private BuildUrl lastCompletedBuild;
private BuildUrl lastFailedBuild;
private BuildUrl lastStableBuild;
private BuildUrl lastSuccessfulBuild;
private BuildUrl lastUnstableBuild;
private BuildUrl lastUnsuccessfulBuild;
public boolean isLastBuildEmpty() {
return lastBuild == null;
}
public Long getLastBuildNumber() {
return isLastBuildEmpty() ? null : lastBuild.getNumber();
}
}
@ToString
@Getter
@NoArgsConstructor
public class BuildUrl {
private String url;
private long number;
}Build 조회 API URL에 Job 이름이 포함되어 있기 때문에 너무 당연해서 그런지 API에서 Job의 이름을 제공하고 있지 않아서, BuildInfo에서는 추후 활용도를 높이기 위해 조회 후 이미 가지고 있는 Job 이름 정보를 업데이트하기로 했습니다.
@ToString
@Getter
@NoArgsConstructor
public class BuildInfo {
private String batchId; // 해당 빌드의 Job Name. API에서 제공하고 있지 않아 수동으로 update 한다.
private String id;
private long number;
private String url;
private boolean building;
private String description;
private String displayName;
private String result;
private long timestamp;
private long duration;
public void updateBatchId(String batchId) {
this.batchId = batchId;
}
public LocalDateTime getBuildStartTime() {
return new Timestamp(timestamp).toLocalDateTime();
}
public LocalDateTime getBuildEndTime() {
return new Timestamp(timestamp + duration).toLocalDateTime();
}
}정산시스템에서는 이미 Jenkins API를 통해 특정 배치를 단건 실행하는 JenkinsConnector라는 모듈이 있었기 때문에, 해당 모듈에 조회 로직을 추가하기로 했습니다.
RestTemplate을 사용해서 Job의 존재 유무를 확인하는 메서드와 JobInfo, BuildInfo를 조회하는 메서드를 각각 작성했습니다.
젠킨스 API를 사용하기 위해서는 젠킨스 환경설정에서 사용자별 토큰을 발급하고, Request에
사용자ID:토큰의 형태로 인증 헤더를 보내면 됩니다.
// JenkinsConnector.java
public boolean existsJob(String batchId) {
try {
String requestUrl = createJobUrl(batchId); // Job 조회 API URL
ResponseEntity<JobInfo> responseEntity = this.restTemplate
.exchange(requestUrl, GET, new HttpEntity<>("", createAuthHeaders()), JobInfo.class);
HttpStatus statusCode = responseEntity.getStatusCode();
return statusCode.is2xxSuccessful();
} catch (Exception e) {
log.error(e.getMessage(), e);
return false;
}
}
public JobInfo getJobInfo(String batchId) {
try {
log.info("address: {}, batchId: {}", address, batchId);
String requestUrl = createJobUrl(batchId); // Job 조회 API URL
return this.restTemplate
.exchange(requestUrl, GET, new HttpEntity<>("", createAuthHeaders()), JobInfo.class)
.getBody();
} catch (Exception e) {
throw new JenkinsExecuteException("Job Info Fetching Exception! ", e);
}
}
public BuildInfo getBuildInfo(String batchId, long buildNumber) {
try {
log.info("address: {}, batchId: {}, buildNumber: {}", address, batchId, buildNumber);
String requestUrl = createBuildUrl(batchId, buildNumber); // Build 조회 API URL
BuildInfo buildInfo = this.restTemplate
.exchange(requestUrl, GET, new HttpEntity<>("", createAuthHeaders()), BuildInfo.class)
.getBody();
if (buildInfo != null) {
buildInfo.updateBatchId(batchId);
}
return buildInfo;
} catch (Exception e) {
throw new JenkinsExecuteException("Build Info Fetching Exception! ", e);
}
}
private HttpHeaders createAuthHeaders() {
String credentials = username + ":" + token;
String base64Credentials = Base64.getEncoder().encodeToString(credentials.getBytes());
HttpHeaders httpHeaders = new HttpHeaders();
httpHeaders.set("Authorization", "Basic " + base64Credentials);
return httpHeaders;
}그리고 서비스 로직에서 이 JenkinsConnector를 사용하여 배치 하나 당 Job 조회, Build 조회를 순차적으로 진행하도록 했습니다.
// MonitoringBatchService.java
public List<MonitoringBatchResponse> search(MonitoringBatchSearchRequest request) {
LocalDate workingDate = request.getWorkingDate();
List<MonitoringBatchResponse> monitoringBatchResponses = monitoringBatchServerRepository.searchByCondition(request);
for (MonitoringBatchResponse monitoringBatchResponse : monitoringBatchResponses) {
updateBuildInfo(monitoringBatchResponse, workingDate); // DB에서 조회한 배치 리스트를 반복문을 돌면서 하나씩 Job, Build 조회
}
// ...
}
private void updateBuildInfo(MonitoringBatchResponse monitoringBatchResponse, LocalDate workingDate) {
String batchId = monitoringBatchResponse.getBatchId();
try {
JobInfo jobInfo = jenkinsConnector.getJobInfo(batchId); // Job 조회
// ...
BuildUrl lastBuild = jobInfo.getLastBuild(); // 최신 Build 번호 확인
if (lastBuild != null) {
BuildInfo buildInfo = jenkinsConnector.getBuildInfo(batchId, lastBuild.getNumber()); // Build 조회
// ... 상태 업데이트
}
} catch (JenkinsExecuteException e) {
log.error("Jenkins 에서 조회할 수 없는 배치 Job 입니다. batchId={}", batchId);
}
}음, 아주 조회가 잘 되는 것을 확인했습니다. 배포! 👏
비동기로 로직 개선
네, 지금까지 과거 회상 씬이었고요.
이제 서문에서의 상황으로 돌아가서 이 무지막지한 API 호출을 손볼 차례입니다.
사실 배치 모니터링은 대시보드의 여러가지 지표 중 지분이 작고 활용도가 적은 부분이라 뒤늦게 인지한 측면도 있었고, 개선 우선순위가 낮기도 했었습니다. 핑계
확인한 당시에는 등록한 배치 수도 50여 개 가까이 되면서 1회 진입 시 호출하는 API 횟수가 100회에 가까웠습니다.
API 호출 100회를 동기식으로 조회하니 속도가 안나오는건 당연할수밖에요.
그래서 비동기 방식으로 슥삭 개선해보기로 했습니다.
비동기 요청을 처리하기 위해 Java8에 등장한 CompletableFuture를 사용하기로 했고, 그전까지 CompletableFuture를 제대로 써본 적이 없었기에 진행에 앞서 개인 블로그에 정리도 해보았는데요.
아래 나올 CompletableFuture의 API를 몇 개만 간단히 정리해보면 다음과 같습니다.
- supplyAsync
- Supplier 타입을 파라미터 콜백으로 받아서 비동기 요청을 수행하고 반환값을 리턴하는 메서드입니다.
- join
- 위 supplyAsync는 콜백의 반환값을 CompletableFuture가 감싼 형태로 리턴을 하는데요. 받은 CompletableFuture가 끝나기를 기다리고 싶다면 join()으로 Blocking을 걸어서 비동기 작업이 끝나기를 기다릴 수 있습니다.
- handleAsync
- 비동기 작업이 끝난 이후, 해당 결과물과 (혹시나 실패했다면) 예외를 파라미터로 받아 종합적으로 후속 작업을 지정할 수 있는 메서드입니다.
- allOf
- 여러 CompletableFuture를 한번에 Blocking 할 때 사용하는 메서드입니다.
CompletableFuture까지 훑어봤으니, 이제 동기 로직을 비동기 로직으로 전환해보도록 하겠습니다!
먼저 기존 어드민 시스템에서 비동기 작업을 담당하고 있던 스레드 풀(Executor)의 설정을 변경했습니다.
// AsyncConfig.java
public static final String ADMIN_DEFAULT_EXECUTOR_NAME = "threadPoolTaskExecutor";
private static final int POOL_SIZE = 30;
@Bean(name = ADMIN_DEFAULT_EXECUTOR_NAME)
public Executor threadPoolTaskExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(POOL_SIZE);
executor.setMaxPoolSize(POOL_SIZE);
executor.setThreadNamePrefix("admin-default-async-");
// ...
return executor;
}다들 아시겠지만 위에 나온 threadPoolTaskExecutor의 속성들을 간단하게 정리해보자면 다음과 같습니다.
- corePoolSize
- 스레드의 최소 유지 개수
- maxPoolSize
- 스레드가 최대로 만들어질 수 있는 개수
- threadNamePrefix
- 해당 스레드 풀 내의 스레드 이름 prefix
원래 어드민에서 사용하던 비동기 작업은 단건 메일 전송, 위의 JenkinsConnector를 이용한 단건 배치 수행 등의 단순 작업만 존재했기에 스레드 풀 설정이 default 값으로 되어 있었습니다.
즉, executor의 corePoolSize는 1, maxPoolSize는 Integer.MAX_VALUE 였습니다.
이를 배치 조회를 위한 다수의 API 호출을 위해 corePoolSize, maxPoolSize를 30개로 상향 조정하였습니다.
다음으로는 젠킨스의 조회를 담당하는 객체를 두고, CompletableFuture를 사용하여 비동기 조회 방식으로 로직을 구성하였습니다.
// BatchJobInfoFetcher.java
private final Executor threadPoolTaskExecutor;
public List<BatchJobItem> fetch(List<String> batchIds) {
List<CompletableFuture<BatchJobItem>> batchJobItemFutures = batchIds.stream()
.map(this::fetchBatchJobItemFuture)
.collect(Collectors.toList());
return CompletableFuture.allOf(batchJobItemFutures.toArray(new CompletableFuture[0])) // (1) 전체 Blocking
.thenApply(Void -> batchJobItemFutures.stream()
.map(CompletableFuture::join)
.filter(Objects::nonNull)
.collect(Collectors.toList()))
.join();
}
// 하나의 스레드에서 JobInfo 조회가 끝나면, 다른 스레드가 BuildInfo 조회 작업을 진행할 수 있도록 handleAsync()를 사용
private CompletableFuture<BatchJobItem> fetchBatchJobItemFuture(String batchId) {
return getJobInfoAsync(batchId) // (2) 비동기로 Job 조회
.handleAsync((jobInfo, jobInfoException) -> { // (3) Job 조회 후 Build 조회
Long lastBuildNumber = jobInfo.getLastBuildNumber();
// ... 검증
return fetchBatchJobItem(jobInfo, lastBuildNumber);
}, threadPoolTaskExecutor);
}
private CompletableFuture<JobInfo> getJobInfoAsync(String batchId) {
return CompletableFuture.supplyAsync(() -> jenkinsConnector.getJobInfo(batchId), threadPoolTaskExecutor)
.exceptionally(e -> {
logErrorWithBatchId(batchId);
return null;
});
}
private BatchJobItem fetchBatchJobItem(JobInfo jobInfo, Long lastBuildNumber) {
CompletableFuture<BatchJobItem> batchJobItemFuture = getBuildInfoAsync(jobInfo.getName(), lastBuildNumber) // (4) 비동기로 Build 조회
.handleAsync((buildInfo, buildInfoException) -> { // (5) Build 조회 후 가공
// ... 검증
return new BatchJobItem(jobInfo, buildInfo);
}, threadPoolTaskExecutor);
return CompletableFuture.allOf(batchJobItemFuture) // Blocking
.thenApply(Void -> batchJobItemFuture.join())
.join();
}
private CompletableFuture<BuildInfo> getBuildInfoAsync(String batchId, long buildNumber) {
return CompletableFuture.supplyAsync(() -> jenkinsConnector.getBuildInfo(batchId, buildNumber), threadPoolTaskExecutor)
.exceptionally(e -> {
logErrorWithBatchId(batchId);
return null;
});
}
private void logErrorWithBatchId(String batchId) { // (6)
log.error("Jenkins에서 조회할 수 없는 배치 Job입니다. batchId={}", batchId); // log.error로 슬랙 알람 발송
}코드가 조금 복잡할 수는 있는데요, 크게는 다음과 같은 흐름입니다. (주석 번호 참조)
- (1) 모든 비동기 요청은 결국 각 요청의 결과값이 모두 다 도착해야 화면 응답을 내려줄 수 있기 때문에, 조회가 끝나고 최종적으로는 CompletableFuture.allOf()로 Blocking을 걸어서 모든 응답이 끝났음을 보장해 줬습니다.
- (2) 먼저 조회해야 하는 batchId 리스트를 보고 순차적으로 Job을 조회하는 비동기 요청을 보냅니다.
- Supplier 타입을 파라미터로 받는 CompletableFuture.supplyAsync()를 사용했습니다.
- (3) Job을 비동기로 조회한 뒤 Build를 조회하는 후속작업을 지정합니다.
- (4) Job 조회에서 얻은 최신 buildId를 사용해 Build를 조회합니다.
- (5) (3)에서와 동일하게 Build를 비동기로 조회한 뒤 Job과 Build를 가공하는 후속작업을 지정합니다.
- (6) 만약 Job이나 Build 조회 시 예외가 발생하면,
log.error(Slf4j)를 남기고 null을 반환하도록 했습니다.- 정산시스템은 log.error가 발생하면 ELK에서 감지 후 슬랙에 에러 알람을 보내도록 되어있습니다.
- null 반환은 기본적으로 안티 패턴이지만, private 메서드로 내부에서만 사용하기 때문에 에러 시 null을 반환하도록 하고, public 메서드에서 필터링하는 용도로 사용했습니다. 한 건의 조회를 실패하더라도 나머지 정상적인 조회 결과는 보여줘야 하기 때문입니다.
이 로직에서 눈여겨봐야 하는 부분은, (2) ~ (5)의 과정에서 모두 같은 스레드 풀(threadPoolTaskExecutor)을 사용하도록 했다는 점입니다.
이렇게 개선을 마치고, 베타 서버에서 조회 속도의 드라마틱한 향상을 체감한 뒤 운영 배포를 진행했습니다! 👏
1차 배포 후

장애가 났습니다.
배포 직후에는 화면에 반응이 없길래 '왜 속도가 안나오지?' 했는데, 알고보니 아예 동작을 하지 않았던 것이었습니다.
더 큰 문제는, 단순히 배치 모니터링 지표만 안나오면 그나마 괜찮은데 어드민의 다른 기능까지 같이 동작하지 않는 이슈가 발생하기 시작했습니다.
이유인즉슨, 스레드 풀에서 데드락이 발생했고, 같은 스레드 풀을 사용하고 있던 몇 없는 비동기 로직(위에서 언급한 메일 전송, 단건 배치 실행 등)까지도 같이 동작하지 않았던 것이었습니다.
위 로직대로라면, 조회 배치 수 >= 스레드 수 의 조건에서는 데드락 현상이 발생합니다.
구체적인 설명을 위해 중복이지만 여러분의 스크롤은 소중하기 때문에 위의 코드를 다시 가져와 보겠습니다.
// BatchJobInfoFetcher.java
private final Executor threadPoolTaskExecutor;
public List<BatchJobItem> fetch(List<String> batchIds) {
List<CompletableFuture<BatchJobItem>> batchJobItemFutures = batchIds.stream()
.map(this::fetchBatchJobItemFuture)
.collect(Collectors.toList());
return CompletableFuture.allOf(batchJobItemFutures.toArray(new CompletableFuture[0])) // (1) 전체 Blocking
.thenApply(Void -> batchJobItemFutures.stream()
.map(CompletableFuture::join)
.filter(Objects::nonNull)
.collect(Collectors.toList())
)
.join();
}
// 하나의 스레드에서 JobInfo 조회가 끝나면, 다른 스레드가 BuildInfo 조회 작업을 진행할 수 있도록 handleAsync()를 사용
private CompletableFuture<BatchJobItem> fetchBatchJobItemFuture(String batchId) {
return getJobInfoAsync(batchId) // (2) 비동기로 Job 조회
.handleAsync((jobInfo, jobInfoException) -> { // (3) Job 조회 후 Build 조회
Long lastBuildNumber = jobInfo.getLastBuildNumber();
// ... 검증
return fetchBatchJobItem(jobInfo, lastBuildNumber);
}, threadPoolTaskExecutor);
}
private CompletableFuture<JobInfo> getJobInfoAsync(String batchId) {
return CompletableFuture.supplyAsync(() -> jenkinsConnector.getJobInfo(batchId), threadPoolTaskExecutor)
.exceptionally(e -> {
logErrorWithBatchId(batchId);
return null;
});
}
private BatchJobItem fetchBatchJobItem(JobInfo jobInfo, Long lastBuildNumber) {
CompletableFuture<BatchJobItem> batchJobItemFuture = getBuildInfoAsync(jobInfo.getName(), lastBuildNumber) // (4) 비동기로 Build 조회
.handleAsync((buildInfo, buildInfoException) -> { // (5) Build 조회 후 가공
// ... 검증
return new BatchJobItem(jobInfo, buildInfo);
}, threadPoolTaskExecutor);
return CompletableFuture.allOf(batchJobItemFuture) // Blocking
.thenApply(Void -> batchJobItemFuture.join())
.join();
}
private CompletableFuture<BuildInfo> getBuildInfoAsync(String batchId, long buildNumber) {
return CompletableFuture.supplyAsync(() -> jenkinsConnector.getBuildInfo(batchId, buildNumber), threadPoolTaskExecutor)
.exceptionally(e -> {
logErrorWithBatchId(batchId);
return null;
});
}
private void logErrorWithBatchId(String batchId) { // (6)
log.error("Jenkins에서 조회할 수 없는 배치 Job입니다. batchId={}", batchId); // log.error로 슬랙 알람 발송
}예를 들어 조회할 배치 2개, 스레드 풀의 스레드 수를 2개라고 가정해 보겠습니다.
2개의 스레드가 2개의 배치를 조회 및 가공하는 (2) ~ (3) 번 과정을 수행합니다.
문제는 fetchBatchJobItem() 이라는 (4) ~ (5)의 과정이 (3)의 과정에 포함되는 작업이기 때문에, (2)번 과정에 모든 스레드가 물려있는 상황에서 새로운 (4) ~ (5)번 작업을 위한 스레드를 요청하게 되고, 이는 곧 각자의 스레드가 서로가 끝나기만을 기다리는 데드락 현상으로 이어집니다.
당시 운영에서 등록해 조회하고 있던 배치는 47개 정도여서, 해당 이슈는 핫픽스 배포로 스레드 풀의 개수를 초기 설정 30개에서 50개로 상향 조정하여 임시 조치하는 방식으로 해소하였습니다.
이후 정확한 원인 파악을 진행하고, 두 가지 후속조치를 진행하였는데요.
첫 번째는 어드민의 기존 기능들이 사용하는 스레드 풀과 대시보드 전용 스레드 풀을 분리하였습니다.
후에 대시보드에서 또 다른 스레드 이슈가 발생하더라도 다른 기능들은 영향을 받지 않게끔 하기 위해서입니다.
두 번째는 (2), (4)번 과정의 네트워크 조회 로직만 대시보드 전용 스레드 풀을 사용하게 하고, (3), (5)번 과정의 애플리케이션 단에서의 단순 가공 로직은 기본 제공되는 Tomcat의 NIO 스레드 풀을 자연스럽게 이용할 수 있도록 특별한 스레드 풀 지정을 하지 않았습니다.
(지금 생각해보면 스레드 풀 지정을 하지 않는 것보다, 또 다른 스레드 풀을 두고 별도로 지정하는 것이 더 좋았을 것 같습니다. 톰캣의 스레드 풀은 스레드 생성 제한이 없어서 자칫하면 위험할 수 있기 때문입니다.)
이렇게 하면 대시보드 스레드 풀의 스레드들이 정확히 네트워크 리소스에만 투입되고, 서로의 작업 간에 pending 되는 일이 없게 됩니다.
위 후속 조치에 따라 2차 개선한 코드는 다음과 같습니다.
// AsyncConfig.java
public static final String ADMIN_DEFAULT_EXECUTOR_NAME = "adminExecutor";
public static final String MONITORING_BATCH_EXECUTOR_NAME = "monitoringBatchExecutor";
private static final int MONITORING_BATCH_THREAD_POOL_SIZE = 10;
@Bean
@Qualifier(ADMIN_DEFAULT_EXECUTOR_NAME)
public Executor adminExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setThreadNamePrefix("admin-async-");
// ...
return executor;
}
@Bean
@Qualifier(MONITORING_BATCH_EXECUTOR_NAME)
public Executor monitoringBatchExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(MONITORING_BATCH_THREAD_POOL_SIZE);
executor.setMaxPoolSize(MONITORING_BATCH_THREAD_POOL_SIZE);
executor.setThreadNamePrefix("monitoring-async-");
// ...
return executor;
}AsyncConfig.java에서는 스레드 풀을 2개로 분리하고, 대시보드 스레드 풀의 크기를 10개로 조정하였습니다. (필요 이상으로 스레드가 많을 필요도 없기 때문에 운영 상황을 보면서 조절하는 것이 좋습니다.)
// BatchJobInfoFetcher.java
// ...
private CompletableFuture<BatchJobItem> fetchBatchJobItemFuture(String batchId) {
return getJobInfoAsync(batchId)
.handleAsync((jobInfo, jobInfoException) -> { // (3) Job 조회 후 Build 조회
Long lastBuildNumber = jobInfo.getLastBuildNumber();
// ... 검증
return fetchBatchJobItem(jobInfo, lastBuildNumber);
}); // 별도의 스레드 풀 지정하지 않음
}
private CompletableFuture<JobInfo> getJobInfoAsync(String batchId) {
return CompletableFuture.supplyAsync(() -> jenkinsConnector.getJobInfo(batchId), threadPoolTaskExecutor) // 기존처럼 스레드 풀 지정
.exceptionally(e -> {
logErrorWithBatchId(batchId);
return null;
});
}
private BatchJobItem fetchBatchJobItem(JobInfo jobInfo, Long lastBuildNumber) {
CompletableFuture<BatchJobItem> batchJobItemFuture = getBuildInfoAsync(jobInfo.getName(), lastBuildNumber)
.handleAsync((buildInfo, buildInfoException) -> { // (5) Build 조회 후 가공
// ... 검증
return new BatchJobItem(jobInfo, buildInfo);
}); // 별도의 스레드 풀 지정하지 않음
return CompletableFuture.allOf(batchJobItemFuture) // Blocking
.thenApply(Void -> batchJobItemFuture.join())
.join();
}
private CompletableFuture<BuildInfo> getBuildInfoAsync(String batchId, long buildNumber) {
return CompletableFuture.supplyAsync(() -> jenkinsConnector.getBuildInfo(batchId, buildNumber), threadPoolTaskExecutor) // 기존처럼 스레드 풀 지정
.exceptionally(e -> {
logErrorWithBatchId(batchId);
return null;
});
}
// ...젠킨스 로직에서는 (3), (5)번 과정에서 대시보드 스레드 풀을 지정하던 부분을 제거하였습니다.
다음 로그를 보시면, 빨간색 박스의 비동기 로직을 요청하는 메인 스레드는 톰캣의 스레드 풀(NIO)을 사용하고 있는 것을 볼 수 있고, 파란색 박스의 실제 Jenkins API 요청은 직접 지정한 스레드 풀(monitoring-async)을 사용하는 것을 확인할 수 있습니다.
메인 스트림 스레드와 API 요청 스레드가 분리되었기 때문에 데드락이 걸리지 않게 된 것이죠.

여러 케이스를 테스트하면서 안전성을 두번 세번 확인 후, 다시 2차 배포를 진행했습니다! 👏
2차 배포 후

추가 배포 후 다행히 10개의 스레드로도 기능은 잘 동작했고, 조회 속도도 기대한만큼 나와주었습니다.
기존 90초 걸리던 로직이 2초 이내로 개선이 되어 무려 44배의 성능 개선율을 보여주었습니다.
추가 개선 예정 + Outro
개발 당시에는 비동기 호출 구조에만 정신이 팔려서 인지하지 못하고 있었는데, 이번에 글을 다시 작성하면서 정리하다보니 위 내용은 다음과 같이 개선 가능하다는 사실을 깨달았습니다.
현재는 하나의 배치를 기준으로 보면 Job 조회 → 최신 Build Id 얻음 → Build 조회 로 항상 Job을 조회한 후 Build를 조회하도록 순차적으로 진행하고 있는데요.
꼭 Job 정보를 찔러서 최신 Build Id를 알아낸 뒤에 해당 Id 값을 사용해 조회하지 않아도, Jenkins API URL에 lastBuild, lastCompletedBuild 등과 같이 고정된 문자열을 사용해서 최신 Build에 대한 조회가 가능하다고 합니다. 이럴수가?
이렇게 되면 ${Jenkins_URL}/job/${job_name}/lastBuild/api/json 로 특정 Job에 대한 최신 Build 조회가 가능하니, 굳이 Build를 조회하기 전에 Job을 조회하지 않아도 되고, 같은 레벨에서 Job과 Build를 동시에 조회하고 조합하는 구조로 개선할 수 있겠다는 생각이 들었습니다.
즉, 지금은 Job 50개를 먼저 다 조회한 후, Blocking을 걸어 작업 완료가 보장되면 그 다음 순서로 Build 50개를 조회하는데, 위 구조대로라면 총 100개의 요청을 순서 상관없이 동시 요청하고, 조회 완료 후에는 Map 등으로 가공 로직을 거쳐 원하는 형태의 Job + Build 응답값을 구성할 수 있겠다고 판단을 했습니다.
요 3차 개선 구조는 조만간 시간이 나면 바로 개선을 진행해볼 예정입니다. 조회 시간도 기대만큼 1초 대로 좀 더 단축이 되면 좋겠네요.
만들고 개선하고 장애내고 다시 개선하는 일련의 과정을 거치면서, 비교적 친숙하지 않았던 비동기 로직의 맛을 슬쩍 볼 수 있어서 다 끝나고 나서는 즐거웠습니다.
무엇보다 미리 데드락 상황을 로컬에서 충분히 재현하고 예측할 수 있었는데 그러지 못한 점이 가장 아쉬웠고요. 이런 경험을 통해, 또 몇 달 시간이 지났지만 글로 한번 더 정리하면서, 조금 더 Real-정산지기를 향해 한걸음 더 나아갔다고 되돌아볼 수 있는 소중한 경험이었습니다.
긴 글 읽어주셔서 감사합니다-! 😉
'jenkins' 카테고리의 다른 글
| jenkins-rest 로 Jenkins API 사용하기 (0) | 2020.04.09 |
|---|